


Journal Club: 'Reclaiming AI as a theoretical tool for cognitive science.'
showcasing - perhaps despite the intent of the authors - the importance of AI safety

"Reclaiming AI as a theoretical tool for cognitive science", by van Rooij et al., is a recent preprint by a team of cognitive scientists trying to counteract the AI hype. It argues from what seems like a position of exasperation at the hyperbole and bravado that gets thrown around wherever there are neural networks (and especially LLMs) these days, from scientists who just want tools to be represented and used correctly. It does so by first constructing a formal proof that "AI-by-learning" is an NP-hard problem, and then relating AI-by-learning to the problem faced by researchers. They also talk about how the conception of AGI as imminent and like-current-systems impoverishes the view of human cognition. In the second part of the paper they rebut what is known as computational 'makeism', the view that we can easily understand cognition by creating it, and present instead some desirable characteristics of a productive theory and view of AI for cognitive science.
In this post I will focus mostly on the first part of their paper. I will summarise and comment on:
their discussion about how the term AI is used today
the paper's focus on human-like or -level systems
The formalization and intractability proof
And give a brief outline of what their vision of a theory without makeism looks like, before ending on some thoughts on how I think this paper interacts with AI safety ('notkilleveryoneism').
The proliferation and hype of "AI"
The first point brought up is the proliferation of AI "use-cases" nowadays:
present-day AI hype and the popularity of AI as technology and AI as money-maker seems to leave little room for AI as a theoretical tool for cognitive science.
I resonate a lot with this point; I think the term "AI" is bandied around a lot, and that the meaning of the term has become diffuse and therefore confused. I really, really dislike this general trend. It causes confusion with regards to what AI systems do (planning, decision, learning, generative), and how they are constructed (classic vs. neural nets vs. specifically LLMs), and lets companies get away with vague statements about using “AI” without specifying the model1. In general conversation, I always try to disambiguate when talking about LLMs, AI in general, image models. or more classicaly planning or inference systems. This also ties into the notes on Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models; trying to explain to the general public the differences in AI models and the make-up of the useful tools that are out there.
van Rooij et al. go on to say:
First, we set out to release the grip of the currently dominant view on AI (viz., AI-as-engineering aiming at a human-level AI system). This practice has taken the theoretical possibility of explaining human cognition a a form of computation to imply the practical feasibility of realising human(-like or -level) cognition in factual computational systems; and, it is framing this realisation as a short-term inevitability.
This part I'm partially in strong agreement with, while on the other hand I partially think it's kind of...naïve? Clearly the short-term inevitability of AGI is unknown, but any tech company in the modern age seems like it would start making large claims about the inevitability of (capabilities) progress on their technology. I consider it a basic fact by now that hype sells, and me disliking that isn't going to change it. So while it would be nice if AI as a theoretical tool gained ground on the other conceptions, I don't know how to make that happen, nor do I know if this attempt - a fairly obscure mathematical proof relating to the engineering task faced - will penetrate any of the public consciousness, AI engineers, prospective students of Cognitive Science/AI/ML, or AI hype-bros.
The focus on human(-like or -level) systems
The article places a central focus on 'human(-like or -level)' systems:
Second, we propose a way to return to the idea of AI as a theoretical tool without falling in the trap of confusing our maps for the territory. (...) we think it is vital that the idea of cognition as computation (...) is not mistaken for the practical feasibility of replicating human minds in machines (which we prove is not feasible).
While this is fair and the obvious focus of a group of cognitive science researchers, and indeed the stated goal of many current companies etc., I don't think the companies are committed to anything human-like; rather, the human-like-ness metrics are salient, obvious, and eye-raising. It seems to me more likely that the loop goes something like: we try a thing. that thing means the system performs better on some metric. Because humans are the cognitive system we know that perform well on a bunch of metrics, the engineers might think "might humans work like this?". The comparisons to humans is so easy to make, and so quick, because humans are the only other cognitive system we've got empirical evidence of. So it’s not that the human metrics are core or sacred to the modern industry of AI - they’re just easy.
This does however lead into one of the other facets where I think the article has a really strong point; taking these kinds of analogies too far really does "create distorted and impoverished views of ourselves and deteriorates our theoretical understanding of cognition". While Scott Alexander has a point2 when he asks to what extent people are also “just” ‘fancy autocomplete’, I think there is a version of taking that too far. The very simple, very short answer to “is anything we’ve come up with importantly like humans”, is “look around”.
Because it will be useful for the remainder of this post, I would like to explicitly distinguish between human-like systems and human-level systems, which the original authors do not. Note that this is just my interpretation of these words, I'm sure there are other good ones out there, and I'm sure that van Rooij et al. thought a lot about which words to use and why:
Human-level systems; are systems that can do any task a human can do. This can be operationalised as narrowly as economic tasks, or even as broadly as any task any person might be expected to perform. For example, a human-level system could figure out and carry out the best strategy for calming and/or nurturing an infant. So it might emulate human-like behaviour for the purpose of carrying out this task.
Human-like systems; are a narrower class of systems than the human-level ones. While these can do all the human-level systems can do, they are systems which additionally display other properties we generally associate with humans, like; a sense of morality, an "inner monologue", pro-sociality, etc. To compare with the analogy for human-level systems, a human-like system might not explicitly calculate the best strategy for nurturing an infant; rather, it would feel a sense of care and responsibility for the welfare of the infant, and take actions that it expects would lead to the infant being better off.
From this, I hope it's clear how I think of human-like systems as a narrower class; not only do they do the things humans do, along important dimensions they also are like humans. It is my great hope that either we find a way to reach human-like systems, or that we pause in our development of human-level systems; because on the current trajectory, I'm uncertain that a human-level system wouldn't display Instrumental Convergence.
The Formalization and intractability proof
From here, van Rooij et al. "reveal why the claims of the inevitability of AGI walk on the quicksand of computational intractability." by constructing the "AI-by-learning" problem. If you want the full details, go read the paper, but in summary:
Dr. Ingenia magically has perfect access to any machine learning model, perfect sampling of the environment, & perfect data (a distribution of human behaviour), and which they can use to:
create a program that when implemented and run generates behaviours when prompted by different situations. The goal is to generate with non-negligible probability an algorithm that behaves (approximately) human-like, in the sense that it is non-negligibly better than chance at picking behaviours.
(...)
there is a finite set of behaviours and that for each situation there is a fixed number of behaviours that humans may display in a situation.
the original text contains LaTeX characters, but substack doesn’t really do well with in-line LaTeX. Apologies to the authors, but I think this is the better of bad solutions.
And end up with the following formalization:

From here, they do a proof by contradiction through a reduction from another intractable (NP-hard) problem, "Perfect-vs-Chance" (P-v-C), to AI-by-Learning. For those unfamiliar, a reduction is a proof method used in complexity-theory problems. First, you assume that you can solve your problem of interest (Here, AI-by-Learning, or AI-b-L) in polynomial (tractable) time. Then you show that you can transform another, known NP-hard problem (here, P-v-C) to your problem (AI-b-L) in polynomial time. Then your assumption must be wrong, because otherwise you've shown a way to tractably solve an NP-hard problem.
While the authors do note:
This also means that there exists an algorithm that can approximate the distribution, namely, the algorithm that generates. But there may also be many more algorithms that deviate in some way from human cognition but whose behaviour is still sufficiently human-like.
and:
This argument applies not only to AIs mistaken for models of (all of human) cognition, but for models of substantive cognitive capacities, like language, problem solving, reasoning, analogizing, or perception (Cummins, 2000; van Rooij & Baggio 2021). This can be argued by contradiction. Assume it were possible to tractably make approximate models of such core capacities, or even of restricted capacities, such that one could make piecemeal models of human cognition. Then one would not be able to put them back together tractable in order to account for all of human cognition, because if one were able to, then one would have a tractable procedure for modelling all of cognition, which is an intractable problem (see also Rich, de Haan, Wareham & van Rooij, 2021).
I think this kind of...buries the lede/begs the question? Surely the "attack surface" here matters - I don't think their analysis precludes the possibility that the problem of finding something human-level is tractable (while human-like is intractable - which is the alignment problem in a coat and fake moustache). And then there's the thing where AI cognitive capacity "stopping" at human-level seems unlikely, so the better metric might be 'human-level or higher'.
It's important to note here that the argument by contradiction in the second quote block refers specifically to the intractability of putting these piecemeal models back together to form human cognition, which is, again, not necessarily the relevant target.
Additionally, I think this is also more in line with (the profit incentives of) the relevant companies. They are not strictly aiming at something human-like but (by the earlier definition), at something human-level or better.
In the end, I think the nuances of the proof probably matter for the resolution of this point, and I might do a deep-dive into it once I gain the mathematical acumen to actually follow it. However, for now I am unsure what to believe; does the intractability follow from the assumption of hitting the (relatively small) target of human-like and -level behaviours, or does it also extend to any algorithm which is human-level or "better", where better is in terms of intelligence (thinking true things, achieving goals). On the whole, though, this paper has made me rethink how far away we are from AGI-through-ML, and I now think it's further off than I did before I read the paper.
The reclamation
The second half of the paper focuses on the positive aspects of AI as a tool for theoretical modelling in cognitive science. The authors start by laying out what makeism is, and the pitfall it easily falls into:
The view that computationalism implies that (a) it is possible to (re)make cognition computationally; (b) if we (re)make cognition then we can explain and/or understand it; and possibly (c) explaining and/or understanding cognition requires (re)making cognition itself.
(...)
Note that it is especially easy for makeists to fall into map-territory confusion - mistaking their modeling artefacts for cognition itself - due to the view that the made thing could be cognition.
So what do they want to keep?
Levels of Explanation (Marr)
Capacities as problems - what computational problems does a capacity solve?
Algorithms and simulations - assessing properties of computational theories under its different instantiations
Underdetermination - connects with levels of explanation and the multiple realisability of computational problems (as multiple algorithms/implementations)
Computational realisability - in-principle computability/tractability
Slow (computational cognitive) science
How and why I think this paper recapitulates AI Safety
One more point I want to make relateing AI Safety and this paper is this:
The argument for concern about existential risks due to advanced artificial intelligence does Not go like this: "because we are about to hit 'AGI' soon, therefore we and our area of research is important." Rather, it goes more like "Any advanced artificial intelligence is by default a) unlikely to pursue the goals and objectives humans would want it to pursue and b) unlikely to be easily 'controllable' or 'steerable'. Therefore, regardless of how far away advanced AI is, we should try to do research (and engineering) into those topic areas." I think it's fine to disagree with this - there are several moving parts here - but don't go arguing against the first point thinking it will touch on any cruxes I currently hold.
So in a sense, this paper - and the computational proof they show - is an argument that could very easily be amended to provide support for the existential risk position: reaching a human-like system is computationally intractable, but reaching the way broader class of "systems that can perform most economic tasks (without regard for any other human qualities) is more likely", and this broader class of systems are the ones that won't necessarily do what we want, or take input from us. By default, any advanced system we create is highly unlikely to be human-like; it's way more likely to come from the broader class of human-level systems! And even if it's not a human-level system; maybe it's more or less capable than exactly that, we still shouldn't expect it to hit the very specific point-in-space which is human-like.
Conclusion
While this paper argues clearly and coherently for its position, and there's nothing wrong with its proof, I ultimately don't agree fully with their claims about AGI non-inevitability, because I see the target-to-be-hit as so much wider than what seems to be assumed here.
I don't necessarily think there's anything inevitable about human-level-or-better systems using our current methods3, but I haven't shut it out yet either, and while this argument made me revise some instinctive estimates upwards, I find there to be flaws in the 'scaffolding' (so to say) around their mathematical proof that hinders me from following the authors to their conclusion.
On the “AI Alignment Chart” (no not that kind of alignment), made by statistics educator extraordinaire Richard McElreath, I’m algorithm neutral and ability neutral-rebel, but that doesn’t mean I don’t think clarity in communication is important!
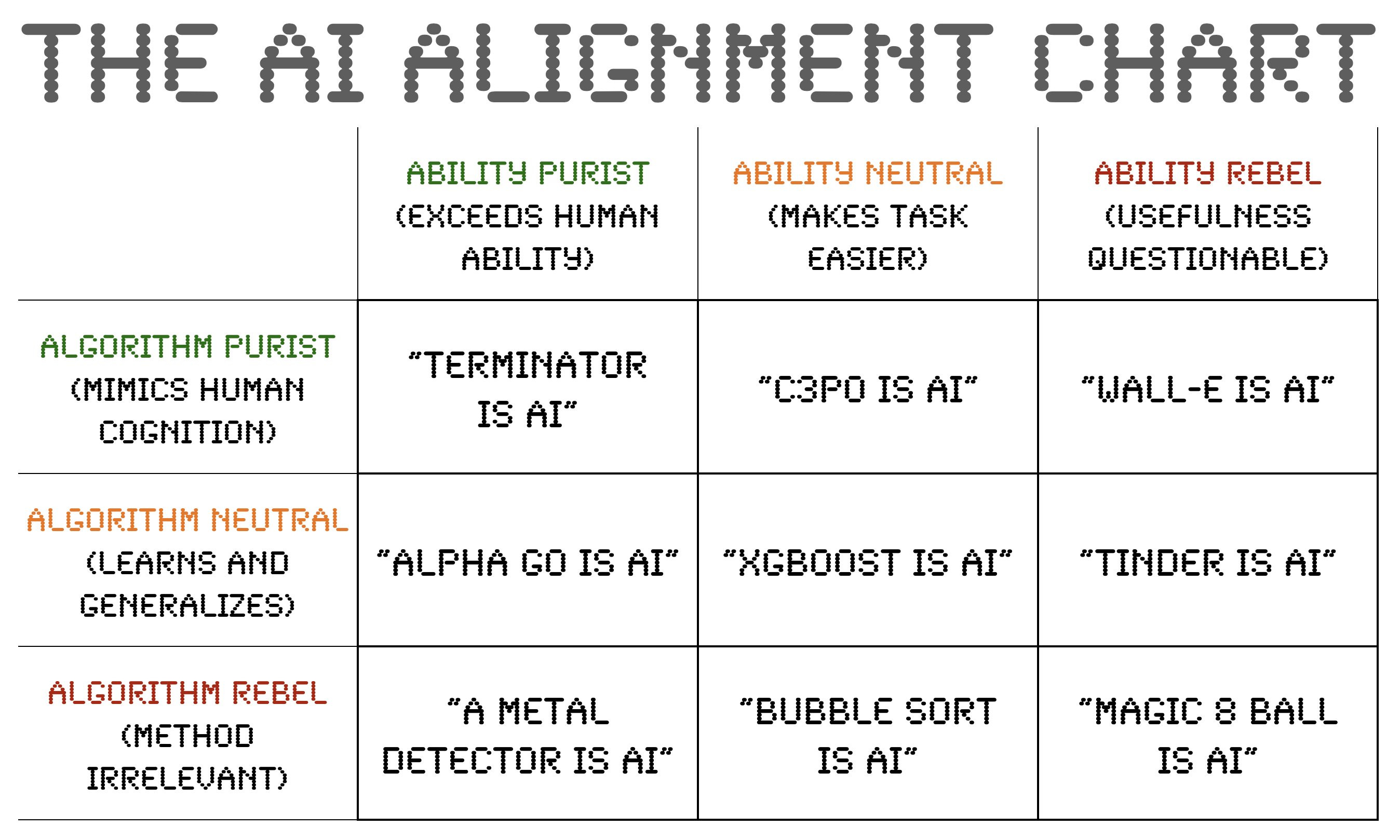
https://x.com/rlmcelreath/status/1694296270540554405?s=20
EDIT: h/t to Anna, I think this is the post I was thinking of: https://slatestarcodex.com/2019/02/19/gpt-2-as-step-toward-general-intelligence/. OLD: I don’t think it’s this post but a quick look through the ACX archives didn’t produce what I remembered to have read; I think it was mostly an argument against “stochastic parrot”, but it might have been something more too. If you can find it i’ll be very grateful.
There’s some claims about the limits of transformers I keep meaning to read, but haven’t got the time or opportunity yet.
Maybe it's this SSC article you were looking for? (people=fancy autocomplete) https://slatestarcodex.com/2019/02/19/gpt-2-as-step-toward-general-intelligence/